
概要
Redashとかのレポートツール便利ですよね。SQLを書いて、表形式で表示するのが非常に楽に実現できます。ただレポートツールなので、条件を入れて集計した結果を保存しておくことができません。現在値の表示は可能ですが、毎日の差分を確認するためにはDWHみたいな大掛かりな仕組みや、バッチサーバーで時系列DBに入れ直すなどの手間がかかります。
そこで、Redashのクエリを取得日時のデータを入れて時系列でそのまま保存してくれるツールを作ってみました。
作成物
Query Result Store (QRS)という名前で作りました。
保存先DBの確保
このツールはSQLite、MySQL、PostgreSQLに対応しています。基本的な動作確認はSQLiteで問題ないのですが、データを大量に保存する場合にはちゃんとしたDBに保存をおすすめします。
収集専用のユーザーをつくりAPIキーを取得
Redashの連携はクエリ単位のAPIキーと、ユーザー単位のAPIキーがあります。クエリ単位のキーを使ったほうがよさそうに思えるのですが、クエリの更新処理などができないのでユーザー単位のAPIキーがだいたい必要となります。
自分のユーザーのAPIキーを使うと退職時とかにユーザーが消えてしまって、仕組みが止まるのでこの手の処理は専用のBOTユーザーを作り、そのAPIキーを取得しましょう!
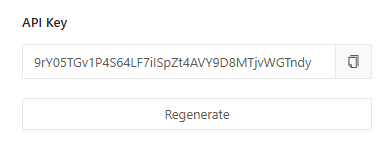
右上のメニューからEdit Profieを開くことでAPIキーが確認できます。
Redashインスタンスの登録

最初にRedashを登録します。RedashへのアクセスURLとAPIを入れることで登録可能です。
データセット登録
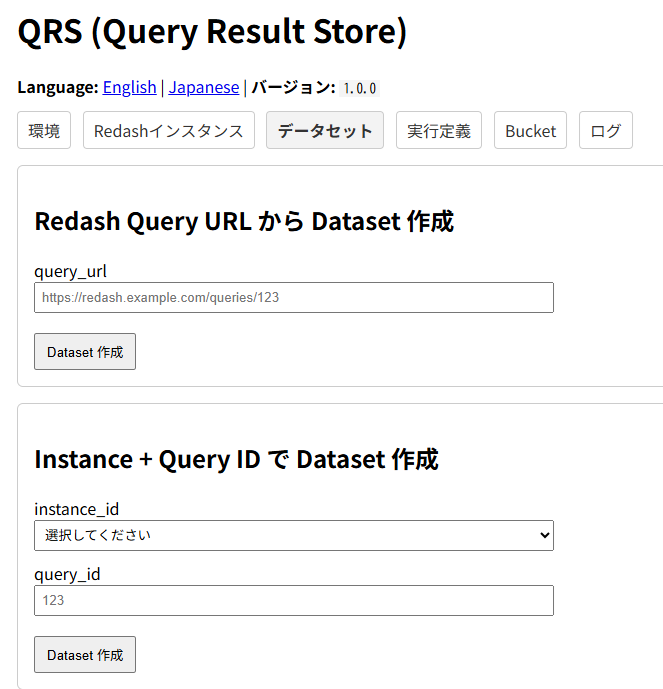
クエリのことをデータセットと呼んでいます。クエリのURLをセットするか、インスタンスとクエリIDを指定してデータセットを登録します。
実行定義
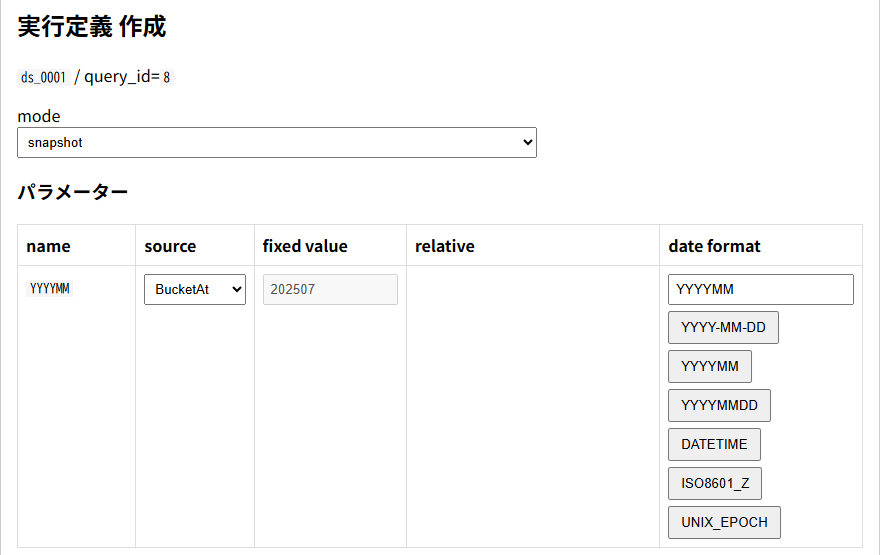
これが肝の部分です。時系列の場合にはモードをスナップショットにして、パラメーターを自動生成します。クエリに複数のパラメーターがある場合にはここで固定値なのか、日付から自動生成するのかを指定します。上記の場合には月次集計でYYYYMMを指定しています。
バケットという単位でデータを処理していて、月次の場合にはその月の1日の日付が入っています。
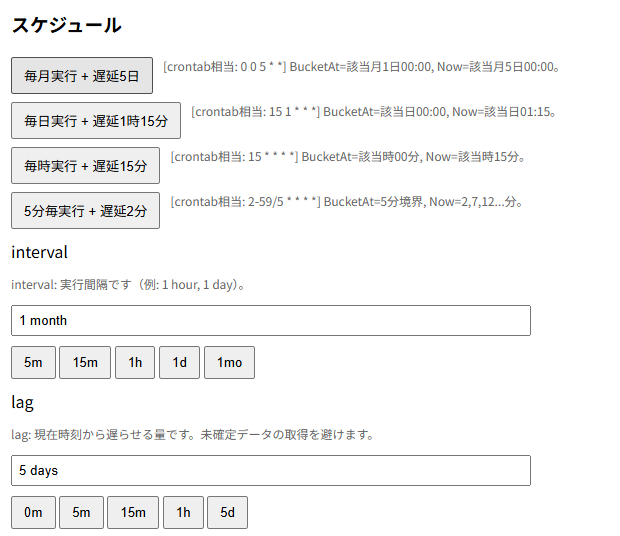
スケジュールが実行頻度になります。まずはインターバルで毎日なのか毎月なのか、5分ごとなのかを指定します。その後にラグでどれぐらい遅延して実行するかを指定します。毎月の集計だけど5日に処理する場合にはインターバルが1月でラグが5日に設定。5分ごとの集計だけど開始時間をバケットの日付に設定するため、集計の締めで+5分、さらに処理待ち時間を入れてラグ9分とかに設定すると、0時0分から0時5分までの集計データを0時9分に取得するみたいな設定になります。
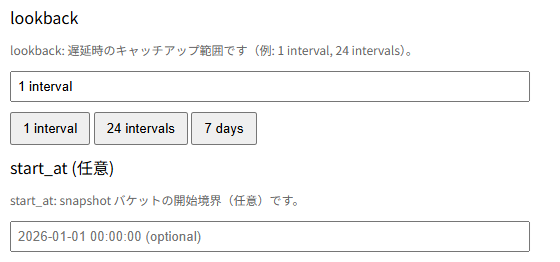
ルックバックは、過去分をどこまで取り込むかになります。最初は5インターバルとか小さい数値で動かしてみて、大丈夫であれば編集から広げていく運用がおすすめです。最初からでかい数値を入れるとずーっと取得し続けるので重いです。スタート日時を入れることで、ルックバックに適当な大きさを入れても、その日付以上前には遡らないガードとなります。
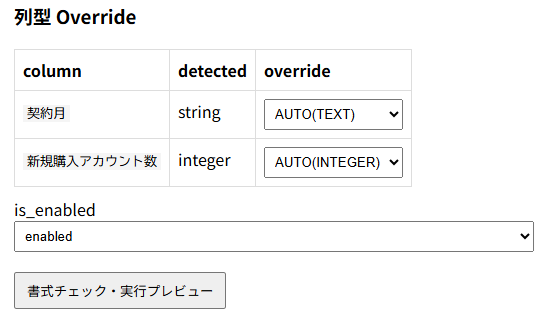
列型は実際のDBのカラム型になります。あとで変更できないので慎重に設定する必要があります。Redashの設定でたまに変更されるので、変更されたら取得時にエラーとしています。INT64などが入っている出たとかだと気をつけて設定する必要があります。
実際の取得処理
毎分起動するワーカースクリプトをcronなどで実行します。ただ取得は1分以上になることがあるので多重実行をブロックする必要があります。
* * * * * flock -n /var/www/html/var/qrs-worker.lock php /var/www/html/bin/worker.phpこんな感じでflockを使うのが楽だと思います。Dockerの場合には自動的に定期実行されるので設定する必要はありません。
このワーカーはバケットという時系列ごとのデータ単位で管理され、クエリの結果をバケットの日付とともに保存しています。

細かい設定は上記でできます。個人的には一番上の生データを保存しておくのが好きです。あとでなにか加工することってあるんですよね。取得処理ですが基本は同時接続1ですが、数を増やすと同一データセット(クエリ)に対しては同時取得はしませんが、他のデータセットやRedashに対しては同時取得できるようになります。
デフォルトではキューがあるかぎり150秒まで20件までデータを取得します。キューがなければ即時終了して、次の起動を待ちます。
キュー取得中に異常終了した場合には復旧秒数経過後の実行中状態のものは取得待ちに戻ります。そのためデフォルトで15分以上クエリに時間がかかるものは取得できません。多重実行をしてDB側に負荷を与えることとなります。ただし、リトライ上限回数が3なのでそこまで大量の多重実行にはならないと思います。
保存の仕組み
RedashにAPI連携してクエリを取得して、取得時間などのカラムを追加したテーブルに保存しているだけです。
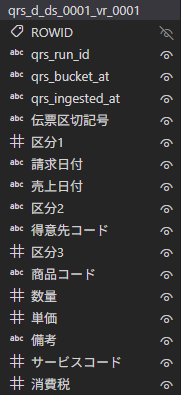
上記がテストで利用したDBのテーブルです。qrs_dのプレフィックスがついているものがこのシステムから生成したデータのテーブルになります。テーブル名でqrs_のものが管理用のカラムで、伝票区切記号からしたが元のRedashクエリのカラムになります。
時系列はバケットで管理しているので、取得時のクエリが全部同一ベケットに保存されています。このテーブルを再度Redashから分析することで、時系列での変化を確認することが可能です。
まとめ
これを使うとGoogleスプレットシートとかからRedashでデータ取得して、そのデータを別のクエリとジョインして表示することができます。デフォルトであるQuery Resultsだとパラメーター付きのクエリをジョインすることができない制約などがあります。
あとは現在値の集計を毎日ためておくとかAIに聞くとDWHを準備しなさいと言われるのですが、それほど簡単に準備できるものではないので、バッチ処理でデータ落とすだけでもしておくとあとで分析が楽になると思います。
ただ実際の環境だと結構自動取得系の処理は重いので、気をつけながら実行する必要があると思います。今回は実際に使う用途というよりは、実験的にどんなことができそうかを学ぶために作ってみました。


コメント